【课程】Basic Econometrics
基于格拉斯哥ECON5002的笔记;
General information
This course introduces modern econometrics, focusing on regression analysis. The goal is to learn enough theory and get enough practice to be able to read journal articles and for conducting basic empirical research.
Aims
The aim of this course is to introduce modern econometrics. The goal is to learn enough theory and get enough practice to be able to read journal articles and for conducting basic empirical research. The emphasis is on applying econometrics to real-world problems. However, a solid understanding of the reviewed inference procedures will require rudiments of probability theory and statistics, and the ability to prove few basic results. The course focuses on regression analysis with cross-section data, under the familiar assumption of random sampling. This setting simplifies the exposition of the main results, requiring assumptions that are relatively straightforward yet realistic. The analysis of time series data is postponed to the last part of the course. This allows highlighting potential pitfalls that do not arise with cross-sectional data. Empirical exercises will be solved during computer lab sessions using an econometric software package.
ILOs
By the end of the course, students should be able to:
Derive some of the fundamental numerical and statistical properties of the OLS estimator.
Critically interpret a regression output to answer a given research question.
Critically evaluate the assumptions of the classical linear regression model and the ways they can be modified and with what effects.
Translate an economic argument into a formal testable hypothesis within a multiple regression model and implement the appropriate testing procedure.
Select the appropriate econometric tools and apply them to implement an empirical analysis using an econometric/statistical software package.
Communicate effectively, using appropriate technical terms.
Work collaboratively in a group to produce a combined output, by liaising with other class members, allocating tasks and co-ordinating
Unit 1:Introduction
Reading: Wooldridge, 7th Edition: Chapter 1
Definition:
Ceteris Paribus: Other factors being equal.
Quiz:
- Income(x) has a causal effect on consumption(y).
- A data set that consists of a variety of other units, taken at a given point in time, is called a(n) cross-sectional data set.
Unit 2:Regression Analysis: Estimation
Unit 2.1:The Simple Regression Model
Reading: Wooldridge, 7th Edition: Chapter 2, including Appendix 2A
Additional (Optional) Reading: Hansen (2020), Sections 2.1-2.9, 2.11, 2.14 and 2.15.
Definition:
Terminology for Simple Regression:
| Y | X |
|---|---|
| Dependent variable | Independent variable |
| Explained variable | Explanatory variable |
| Response variable | Control variable |
| Predicted variable | Predictor variable |
| Regressand | Regressor |
Simple Linear Regression Model:
- intercept parameter: $\beta_0$
- slope parameter: $\beta_1$
error term: $u$
population regression function (PRF):
The Ordinary Least Squares (OLS) Estimator:
OLS regression line/Sample Regression Function (SRF):
Residuals:
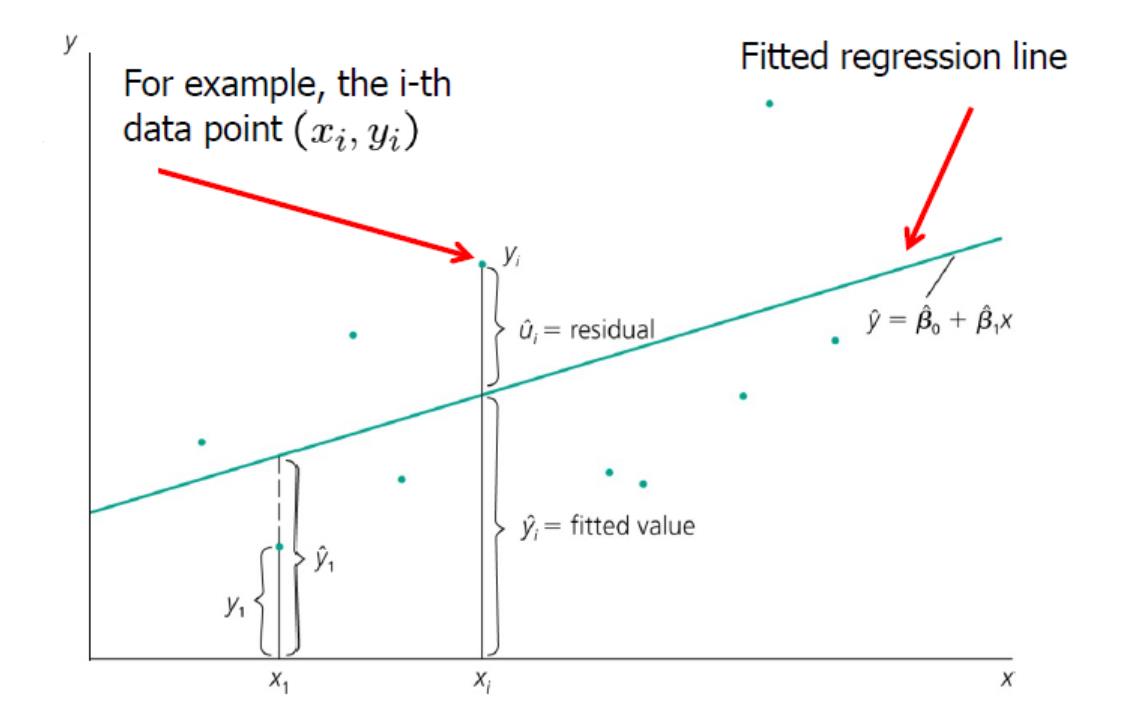
Algebraic Properties of OLS statistics:
- $\sum_{i=1}^n\hat{u}_i=0$
- $\sum_{i=1}^n\hat{u}_ix_i=0$
- $\bar{y}=\hat{\beta}_0+\hat{\beta}_1\bar{x}$
- $\sum_{i=1}^n\hat{y}_i\hat{u}_i=0$
- $\bar{y}=\frac{1}{n}\sum_{i=1}^n\hat{y}_i$
Measures of Variation:
- SST = $\sum_{i=1}^n(y_i-\bar{y})^2$
- total sum of squares
- SSE = $\sum_{i=1}^n(\hat{y}_i-\bar{y})^2$=$\sum_{i=1}^n\hat{\beta}_1^2(x_i-\bar{x})^2$
- explained sum of squares
- SSR = $\sum_{i=1}^n\hat{u}_i^2$
- residual sum of squares
- SST = SSR+ SSR
- $R^2$ = $\frac{SSE}{SST}$ = $1-\frac{SSR}{SST}$, $0\leq R^2 \leq 1$
- coefficient of determination
Summary of Functional Forms Involving Logarithms:
| Model | Dependent Variable | Independent Variable | Interpretation of $\beta_1$ |
|---|---|---|---|
| Level-level | y | x | $\Delta y=\beta_1\Delta x$ |
| Level-log | y | log(x) | $\Delta y=(\beta_1/100)\%\Delta x$ |
| Log-level | log(y) | x | $\%\Delta y=100\beta_1\Delta x$ |
| Log-log | log(y) | log(x) | $\%\Delta y=\beta_1\%\Delta x$ |
Unbiasedness of OLS:
- Assumption SLR.1 (linearity in the parameters)
The random variables $(y_1,x_i)$ satisfy the linear regression equation
- Assumption SLR.2 (random sampling)
- Assumption SLR.3 (sample variation in x)
- Assumption SLR.4 (Zero Conditional Mean)
- $u_i uncorrelate with x$
- Assumption SLR.2 and SLR.4 imply that the (Population) Regression Function is linear.
- Under Assumption SLR.1-SLR.4
Variances of the OLS estimators:
- Assumption SLR.5 (homoskedasticity)
- Under Assumptions SLR.1-SLR.5
Not robust: The expectation is sensitive to perturbation in the tails of the distribution.
y on x
Quiz:
- when the regression equation passes through the origin. $y_i=\beta_1x_i+u_i$
- $\beta_1 = \frac{\sum_{i=1}^nx_iy_i}{\sum_{i=1}^nx_i^2}$
- The observed values of $x$ span a wide range $\to$ SLR.3
Unit 2.1:The Multiple Regression Model
Reading: Wooldridge, 7th Edition: Chapter 3, including Appendix 3A. Chapter 6, Sections 6.1-6.3.
Additional Reading: Hansen (2020), Section 2.30
Definition:
Multiple Linear Regression Model:
- intercept parameter: $\beta_0$
- slope parameter: $\beta_1,…,\beta_k$
Unbiasedness of OLS:
Assumption MLR.1 (Linear in Parameters)
Assumption MLR.2 (Random Sampling)
- Assumption MLR.3 (No Perfect Collinearity)
In the sample (and in the population), none of the explanatory variables is constant, and there are no exact linear relationships among them.
- Assumption MLR.4 (Zero Conditional Mean)
- Under Assumption MLR.1-MLR.4
Omitted Variable Bias:
We should have estimated
but we estimate
Recall that
Bias $(\tilde{\beta}_1|x)$=$\beta_2\tilde{\delta}_1$
if $ n \to \infty$, bias will approach $\frac{Cov(x_{1i},x_{2i})}{Var(x_{1i})}\beta_2$
| $Corr(x_1,x_2)>0$ | $Corr(x_1,x_2)<0$ | |
|---|---|---|
| $\beta_2>0$ | Positive bias | Negative bias |
| $\beta_2<0$ | Negative bias | Positive bias |
Variance of the OLS Estimators:
- Assumption MLR.5 (Homoskedasticity)
Assumptions MLR.1 through MLR.5 are called the Gauss Markov assumptions.
Under Assumptions MLR.1 to MLR.5
- $SST_j = \sum_{i=1}^n(x_{ij}-\bar{x}_j)^2$
- $R_j^2$ is the $R^2$ of the regression
- As $R_j^2 \to 1$, $Var(\hat{\beta}_j) \to \infty$ (the estimate of $\beta_j$ is not precise).
- Under the Gauss-Markov assumptions (MLR.1 through MLR.5)
- standard deviation: $\sigma$; standard error: $\hat{\sigma}$
- The square root of $\hat{\sigma}^2$,$\hat{\sigma}$, is reported by all regression packages (standard error of the regression, or RMSE).
- Under Assumptions MLR.1 through MLR.5
- the OLS estimators are the best linear unbiased estimators (BLUEs)
Variances in Misspecified Models:
We run the misspecified and the correctly specified regressions
Whenever $x_{1i}$ and $x_{2i}$ are correlated, $R_1^2 > 0$, and
- we can in fact get an estimator with a smaller variance, even though it is biased.
Adjusted R-Squared:
Quiz:
- Exclusion of a relevant variable from a multiple linear regression model leads to the problem of misspecification of the model.
- An explanatory variable is said to be endogenous if it is correlated with the error term.
Unit 3:Regression Analysis: Inference
Definition:
Normal distribution in a nutshell
If $x\sim N(\mu,\sigma^2)$, then
- Assumption MLR.6 (Normality of error terms)
- Under assumptions MLR.1 – MLR.6: Classical Linear Regression Model (CLRM) assumptions
- with estimated standard deviation
Note: The t-distribution is close to the standard normal distribution if n-k-1 is large.
Null hypothesis:
Statistically Significant:

Confidence Intervals:
The $\alpha\%$ confidence interval for $\beta_j$ is of the form
- $c_{0.01}=2.576,c_{0.05}=1.96,c_{0.10}=1.645$
- The effect is significantly different from zero if zero is outside the interval.
- It is not statistically significant if zero lies in the interval.
The difference between the estimates:
- $t = \frac{\hat{\beta}_1-\hat{\beta}_2}{se(\hat{\beta}_1-\hat{\beta}_2)}$
- Or Define $\theta_1 = \beta_1-\beta_2$ and test $H_0:\theta_1=0$
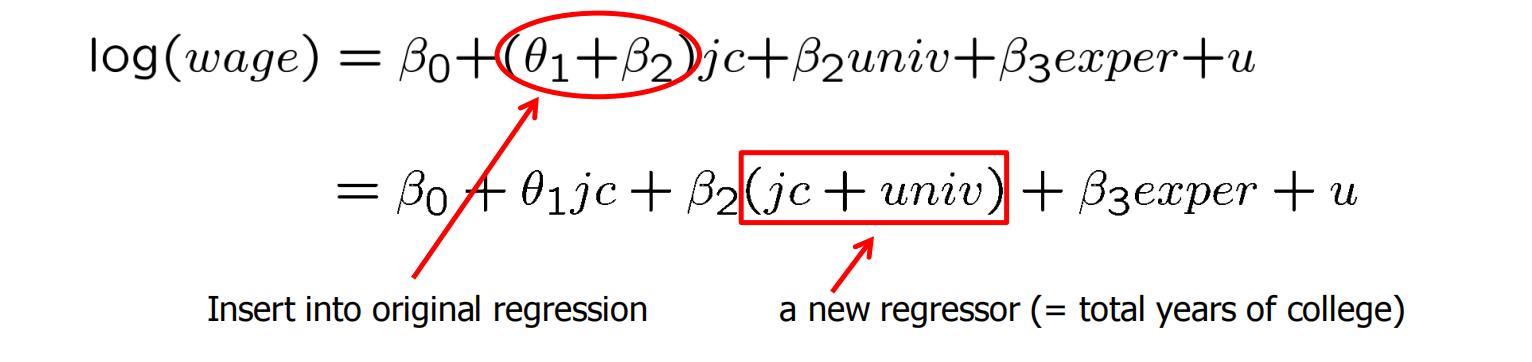
The F-test:
$R^2$ form of the F –statistic:
Test of overall significance of a regression:
Testing general linear restrictions with the F-test:
Quiz:
- The significance level of a test is: the probability of rejecting the null hypothesis when it is true.
- central limit theorem (CLT)
- A restricted model will always have fewer parameters than its unrestricted model./ Degrees of freedom of a restricted model is always more than the degrees of freedom of an unrestricted model.
- The ordinary least square estimators have the smallest variance among all the unbiased estimators.
Unit 4:Regression Analysis with Qualitative Information
Definition:
Dummy variable trap (perfect collinearity) :
When using dummy variables, one category always has to be omitted
Benchmark group
Chow test:
- $H_0$: equality of regression functions across two groups.
We can allow for an intercept difference between the groups, and then test for slope difference. Replace $SSR_p$ in Chow F-stat with the residuals from a regression with a dummy.
Quiz:
- In a self-selection problem, the explanatory variables can be: endogenous.
- Which of the following Gauss-Markov assumptions is violated by the linear probability model (LPM)?
- The assumption of constant variance of the error term.
- $Var(y|x)=p(x)[1-p(x)]$
- Which of the following problems can arise in policy analysis and program evaluation using a multiple linear regression model?
- The model can produce predicted probabilities that are less than zero and greater than one.
- A problem that often arises in policy and program evaluation is that individuals (or firms or cities) choose whether or not to participate in certain behaviors or programs and their choice depends on several other factors. It is not possible to control for these factors while examining the effect of the programs.
Unit 5:Heteroskedasticity
Definition:
Heteroscedasticity: MLR.5 is violated.
Testing for heteroscedasticity:
Breusch-Pagan test:
White test:
Alternative form of the White test:
Weighted least squares estimation:
The functional form of the heteroscedasticity is known
set $w_i=\frac{1}{\sqrt{h_i}}$
where
Observations with a large variance are less informative than observations with small variance and therefore should get less weight
Important special case of heteroscedasticity:
If the observations are reported as averages at the city/county/state/country/firm level, they should be weighted by the size of the unit. $\sigma^2/m_i$
Unknown heteroscedasticity function (feasible GLS) :
White’s Heteroscedasticity-robust standard variance:
Quiz:
- A test for heteroskedasticty can be significant if
- the functional form of the regression model is misspecified
- Breusch-Pagan test/White test results in a small p-value
- The generalized least square (GLS) is an efficient procedure that weights each squared residual by the:
- inverse of the conditional variance of $u_i$ given $x_i$.
- The heteroskedasticity-robust F statistic is also called the heteroskedastcity-robust Wald statistic.
- The linear probability model contains heteroskedasticity unless all the slope parameters are zero.
- The heteroskedasticity-robust t statistics are justified only if the sample size is large.
- In weighted least squares estimation, less weight is given to observations with a higher error variance.
- The WLS method fails if $\hat{h}_i$ is negative or zero for any observation.
- The Hausman test is used to compare the Ordinary Least Squares (OLS) estimates and the Weighted Least Squares (WLS) estimates.
- Multicollinearity among the independent variables in a linear regression model causes the heteroskedasticity-robust standard errors to be large.
- The interpretation of goodness-of-fit ($R^2$) measures is unaffected by the presence of heteroskedasticty.
Unit 6:Regression Analysis with Time Series Data
Reading: Wooldridge 7th Edition Chapter 10: Basic Regression Analysis with the Time Series
Definition:
Finite distributed lag models:
In finite distributed lag models, the explanatory variables are allowed to influence the dependent variable with a time lag
Finite sample properties of OLS under classical assumptions:
- Assumption TS.1 (Linear in parameters)
- Assumption TS.2 (No perfect collinearity)
- Assumption TS.3 (Zero conditional mean)
- (Contemporaneous) Exogeneity is not enough to ensure unbiasdness.
Unbiasedness of OLS
- TS.1-TS.3 $\Rightarrow$ $E(\hat{\beta}_j)=\beta_j, j=0,1,…,k$
Assumption TS.4 (Homoscedasticity)
- $Var(u_t|X)=Var(u_t)=\sigma^2$
Assumption TS.5 (No serial correlation)
- $Corr(u_t,u_s|X)=0, t\neq s$
- Three types of correlation:
- $Corr(x_{jt},x_{hs})$
- $Corr(x_{jt},xu{t})$
- $Corr(u_{t},u_{s})$
OLS sampling variances
- TS.1-TS.5 $\Rightarrow$ $Var(\hat{\beta}_j|X)=\frac{\sigma^2}{SST_j(1-R_j^2)}, j=0,1,…,k$$
Unbiased estimation of the error variance
- TS.1-TS.5 $\Rightarrow$ $E(\hat{\sigma}^2)=\sigma^2$
Gauss-Markov Theorem:
- Under assumptions TS.1 – TS.5, the OLS estimators have the minimal variance of all linear unbiased estimators of the regression coefficients
Assumption TS.6 (Normality)
- $u_t\sim iid N(0,\sigma^2)$ independent of $X$
Normal sampling distributions
- Under assumptions TS.1 – TS.6, the OLS estimators have the usual normal distribution (conditional on $X$ ). The usual F- and t-tests are valid.
Modelling a linear time trend:
Modelling an exponential time trend:
Quiz:
- a static model is postulated when a change in z at time t is believed to have an immediate effect on y
- Adding a time trend can make an explanatory variable more significant if: the dependent and independent variables have different kinds of trends, but movement in the independent variable about its trend line causes movement in the dependent variable away from its trend line.
- Time series regression is based on the assumption that no independent variable is constant nor a perfect linear combination of the others.
- Which of the following assumption for time series analysis does not hold?
- No serial correlation
- One of the assumptions of time series regression is that there should be no serial correlation in the concerned series.
- Cross-sectional regression rules out perfect collinearity among the regressors.
- When a series has the same average growth rate from period to period, it can be approximated with an exponential trend.
- Price indexes are necessary for turning a time series measured in nominal value into real value.
Unit 7:Further Issues Using OLS with Time Series Data
Reading: Wooldridge 7th Edition Chapter 11: Further Issues in Using OLS with Time Series Data
Definition:
Stationary stochastic processes:
A stochastic $\{x_t:t=1,2…\}$ process is stationary, if for every collection of indices $1\leq t_1\leq t_2\leq…\leq t_m$the joint distribution of $(x_{t_1},x_{t_2},…,x_{t_m})$ , is the same as that of $(x_{t_1+h},x_{t_2+h},…,x_{t_m+h})$ for all integers $h\ge1$.
Covariance stationary processes:
A stochastic process $\{x_t:t=1,2…\}$ is covariance stationary, if its expected value, its variance, and its covariances are constant over time:
- $E(x_t)=\mu$
- $Var(x_t)=\sigma^2$
- $Cov(x_t,x_{t+h})=f(h)$
asymptotically uncorrelated:
when $h \to \infty, cov(x_t,x_{t+h}) \to 0$
Weakly dependent time series:
A stochastic process $\{x_t:t=1,2…\}$ is weakly dependent , if $x_t$ is “almost independent” of $x_{t+h}$ if $h$ grows to infinity (for all $t$).
Moving average process of order one (MA(1)):
Autoregressive process of order one (AR(1)):
Asymptotic properties of OLS:
- Assumption TS.1‘ (Linear in parameters)
- now the dependent and independent variables are assumed to be stationary and weakly dependent
- Trend-stationary processes also satisfy assumption TS.1‘
- Assumption TS.2‘ (No perfect collinearity)
Assumption TS.3‘ (Zero conditional mean)
- Now the explanatory variables are assumed to be only contemporaneously exogenous rather than strictly exogenous
Consistency of OLS:
- TS.1‘-TS.3’ $\Rightarrow$ $plim\hat{\beta}_j=\beta_j, j=0,1,…,k$
Assumption TS.4‘ (Homoscedasticity)
- $Var(u_t|x_t)=Var(u_t)=\sigma^2$
Assumption TS.5‘ (No serial correlation)
- $Corr(u_t,u_s|x_t,x_s)=0, t\neq s$
Asymptotic normality of OLS:
- Under assumptions TS.1‘ – TS.5‘, the OLS estimators are asymptotically normally distributed. Further, the usual OLS standard errors, t-statistics and F-statistics are asymptotically valid
Random walks
- $E(y_t)=E(y_0)$
- $Var(y_t)=\sigma_e^2t$
- $Corr(y,y_{t+h}) = \sqrt{t/(t+h)}$
I(1) processes:
Testing for serial correlation
Testing for AR(1) with strictly exog. regressors :
Durbin-Watson test under classical assumptions:
- $H_0 : \rho = 0$
- Reject if $DW
When strictly exogeneity does not hold, t-test and DW test are not valid
Testing for AR(1) with general regressors:
- $H_0:\rho = 0$
General Breusch-Godfrey test for AR(q):
- $H_0:\rho_1=…=\rho_k = 0$
Correcting for serial correlation
with strictly exog. regressors:
Newey-West formula:
- $\hat{\alpha}_t=\hat{r}_t\hat{u}_t$
The integer g controls how much serial correlation is allowed:
- g=2: $\hat{v}=\sum_{t=1}^n\hat{a}_t^2+\sum_{t=2}^n\hat{a}_t\hat{a}_{t-1}$
- g=3:
Serial correlation-robust standard errors:
- $se(\hat{\beta}_j)=[“se(\hat{\beta}_j)/\hat{\sigma}”]^2\sqrt{\hat{v}}$
Quiz:
- Which of the following is a strong assumption for static and finite distributed lag models?
- Dynamic completeness
- $E(y_t|x_t,y_{t-1},x_{t-1},…)=E(y_t|x_t)$
- The problem of serial correlation does not exist in dynamically complete models.
- sequentially exogenous
- $E(u_t|x_t,x_{t-1},…)=E(u_t)=0$
- A model with a lagged dependent variable cannot satisfy the strict exogeneity assumption.
- A random walk process is not stationary.
- Covariance stationarity focuses only on the first two moments of a stochastic process.
- Under adaptive expectations, the expected current value of a variable adapts to a recently observed value of the variable.
- A smaller standard error means: a larger t statistic.
- Consistency of FGLS requires $u_t$ to be uncorrelated with $x_{t-1}$,$x_t$, and$x_{t+1}$
- Prais-Winsten estimation is an example of FGLS estimation.
- Prais-Winsten standard errors account for serial correlation, whereas OLS estimations do not.
- Breusch-Godfrey test can be used to check for second order serial correlation.
- The SC-robust standard errors work better after quasi-differencing a time series that is expected to be serially correlated.
- Consistency of feasible generalized least square estimators requires the error term to be uncorrelated with lags of the explanatory variable. Correlation will lead to inconsistent estimates.
- The Cochrane-Orcutt and Prais-Winsten methods are iterative methods of feasible generalized least square (FGLS) estimation.
- The serial correlation-robust standard errors are typically larger than the usual OLS standard errors when there is serial correlation.