【课程】吴恩达机器学习课程(三)
基于吴恩达机器学习 - Machine Learning Specialization 课程 的笔记第三部分;非监督学习与推荐系统;
Course 3 : Unsupervised Learning, Recommenders, Reinforcement Learning
In the third course of the Machine Learning Specialization, you will:
- Use unsupervised learning techniques for unsupervised learning: including clustering and anomaly detection
- Build recommender systems with a collaborative filtering approach and a content-based deep learning method
- Build a deep reinforcement learning model.
Week 8 : Unsupervised Learning
13. Clustering
13.1 Introduction
在一个典型的监督学习中,我们有一个带标签的训练集,我们的目标是找到能够区分正样本和负样本的决策边界。与此不同的是,在非监督学习中,我们的数据没有附带任何标签,我们拿到的数据就是这样的:
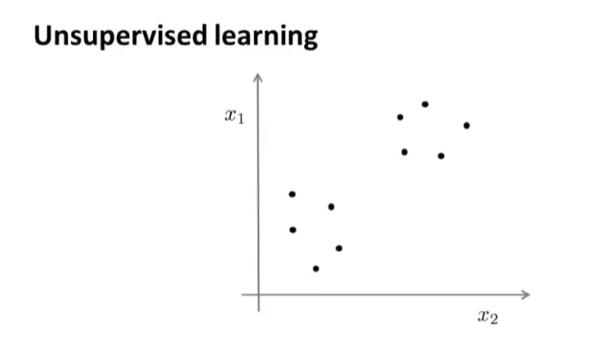
也就是说,在非监督学习中,我们需要将一系列无标签的训练数据,输入到一个算法中。我们可能需要某种算法帮助我们寻找一种结构。图上的数据看起来可以分成两个分开的点集(称为簇),一个能够找到特定点集的算法,就被称为聚类算法。
13.2 Means Algorithm
K-均值 是一个迭代算法,假设我们想要将数据聚类成 $K$ 个组,其方法为:
首先随机选择$K$个随机的点,称为聚类中心(cluster centroids)
对于数据集中的每一个数据,按照距离$K$个中心点的距离,将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类
计算每一个组的平均值
- 将该组所关联的中心点移动到平均值的位置
- 重复步骤2-4直至中心点不再变化。
【Python 代码】
1 | |
【Sklearn Kmeans】
1 | |
13.3 Optimization Objective
K-均值最小化问题,是要最小化所有的数据点与其所关联的聚类中心点之间的距离之和,因此 K-均值的代价函数(又称畸变函数 Distortion function)为:
- $μ^1$,$μ^2$,…,$μ^k$ 表示聚类中心
- $c^{(1)}$,$c^{(2)}$,…,$c^{(m)}$ 存储与第 $i$ 个实例数据最近的聚类中心的索引
- $\mu_{c^{(i)}}$代表与$x^{(i)}$最近的聚类中心点
13.4 Random Initialization
K-均值的一个问题在于,它有可能会停留在一个局部最小值处,而这取决于初始化的情况。为了解决这个问题,我们通常需要多次运行K-均值算法,每一次都重新进行随机初始化,最后再比较多次运行K-均值的结果,选择代价函数最小的结果。
这种方法在$K$较小的时候(2 to 10)还是可行的,但是如果$K$较大,这么做也可能不会有明显地改善。
13.5 Choosing the Number of Clusters
没有所谓最好的选择聚类数的方法,通常是需要根据不同的问题,人工进行选择的。选择的时候思考我们运用K-均值算法聚类的动机是什么,然后选择能最好服务于该目的标聚类数。
当人们在讨论选择聚类数目的方法时,有一个可能会谈及的方法叫作“肘部法则”。关于“肘部法则”,我们所需要做的是改变$K$值,也就是聚类类别数目的总数,然后计算成本函数或者计算畸变函数$J$。随着聚类数目的变大,如果畸变函数下降的速度突然减缓时(在图上表现得像一个凸出的肘部),就应该选择变缓前的最后一个值作为数目。
13.6 其他参考资料
1.相似度/距离计算方法总结
闵可夫斯基距离 Minkowski(其中欧式距离:$p=2$) :
杰卡德相似系数 Jaccard:
余弦相似度 cosine similarity:$n$维向量$x$和$y$的夹角记做$\theta$,根据余弦定理,其余弦值为:
Pearson 皮尔逊相关系数:
Pearson相关系数即将$x$、$y$坐标向量各自平移到原点后的夹角余弦。
2.聚类的衡量指标
均一性:$p$
类似于精确率,一个簇中只包含一个类别的样本,则满足均一性。其实也可以认为就是正确率(每个聚簇中正确分类的样本数占该聚簇总样本数的比例和)
完整性:$r$
类似于召回率,同类别样本被归类到相同簇中,则满足完整性;每个聚簇中正确分类的样本数占该 类型的总样本数比例的和
V-measure:
均一性和完整性的加权平均
轮廓系数 : $s$
簇内不相似度: 计算样本$i$到同簇其它样本的平均距离为$a(i)$,应尽可能小。
簇间不相似度: 计算样本$i$到其它簇$C_j$的所有样本的平均距离$b_{ij}$,应尽可能大。
轮廓系数:$s(i)$值越接近1表示样本$i$聚类越合理,越接近-1,表示样本$i$应该分类到 另外的簇中,近似为0,表示样本$i$应该在边界上;所有样本的$s(i)$的均值被成为聚类结果的轮廓系数。
调兰德指数 : ARI
$a_i$为实际上是 $i$ 这个组,并且聚类成了 $i$ 组的数量
$n_{ij}$为实际是 $i$ 组,被聚类成了 $j$ 组的数量
13.7 K-means in Image Compression

1 | |

【Sklearn Kmeans】
1 | |
14. Dimensionality Reduction
14.1 Motivation
有几个不同的原因使我们可能需要做降维。一是数据压缩,它让我们加快我们的学习算法。二是数据可视化,在许多及其学习问题中,如果我们能将数据可视化,我们便能寻找到一个更好的解决方案,降维可以帮助我们。
14.2 Principal Component Analysis Problem Formulation
主成分分析(PCA)是最常见的降维算法。在PCA中,我们要做的是找到一个方向向量(Vector direction),当我们把所有的数据都投射到该向量上时,我们希望投射平均均方误差能尽可能地小。方向向量是一个经过原点的向量,而投射误差是从特征向量向该方向向量作垂线的长度。
主成分分析与线性回归是两种不同的算法。主成分分析最小化的是垂直到向量方向的投射误差(Projected Error),而线性回归尝试的是最小化 竖直方向的预测误差。线性回归的目的是预测结果,而主成分分析不作任何预测。
PCA技术的一大好处是对数据进行降维的处理。我们可以对新求出的“主元”向量的重要性进行排序,根据需要取前面最重要的部分,将后面的维数省去,可以达到降维从而简化模型或是对数据进行压缩的效果。同时最大程度的保持了原有数据的信息。
PCA技术的一个很大的优点是,它是完全无参数限制的。在PCA的计算过程中完全不需要人为的设定参数或是根据任何经验模型对计算进行干预,最后的结果只与数据相关,与用户是独立的。
但是,这一点同时也可以看作是缺点。如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高。
14.3 Principal Component Analysis Algorithm
PCA 从$n$维减少到$k$维的例子:
第一步是均值归一化。我们需要计算出特征的均值,然后令 $x_j= x_j-μ_j$。如果特征是在不同的数量级上,我们还需要将其除以标准差 $σ^2$。
第二步是计算协方差矩阵(covariance matrix)$Σ$:
第三步是计算协方差矩阵$Σ$的特征向量(eigenvectors)$U$。如果我们希望将数据从$n$维降至$k$维,我们只需要从$U$中选取前$k$个向量,获得一个$n×k$维度的矩阵,我们用$U_{reduce}$表示,然后通过如下计算获得要求的新特征向量$z^{(i)}$:
其中$x$是$n×1$维的,因此结果为$k×1$维度。
14.4 Choosing The Number Of Principal Components
我们希望在平均均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的$k$值。
如果我们希望这个比例小于1%,就意味着原本数据的偏差有99%都保留下来了,如果我们选择保留95%的偏差,便能非常显著地降低模型中特征的维度了。
我们可以先令$k=1$,然后进行主要成分分析,获得$U_{reduce}$和$z$,然后计算比例是否小于1%。如果不是的话再令$k=2$,如此类推,直到找到可以使得比例小于1%的最小$k$ 值
在求svd奇异值分解时我们有式子
其中 $UU^T=I$,更多相关见 连接
其中的$S$是一个$n×n$的矩阵,只有对角线上有值,而其它单元都是0,我们可以使用这个矩阵来计算平均均方误差与训练集方差的比例:
在压缩过数据后,我们可以采用如下方法来近似地获得原有的特征:
【Python 代码】
1 | |
【Sklearn Kmeans】
1 | |
14.5 Advice for Applying PCA
一个常见错误使用主要成分分析的情况是,将其用于减少过拟合(减少了特征的数量)。这样做非常不好,不如尝试正则化处理。原因在于主要成分分析只是近似地丢弃掉一些特征,它并不考虑任何与结果变量有关的信息。因此如果你在监督学习中采用PCA可能会丢失非常重要的性质。然而当我们进行正则化处理时,会考虑到结果变量,不会丢掉重要的数据。
另一个常见的错误是,默认地将主要成分分析作为学习过程中的一部分,这虽然很多时候有效果,最好还是从所有原始特征开始,只在有必要的时候(算法运行太慢或者占用太多内存)才考虑采用主要成分分析。
Week 9 : Anomaly Detection
15. Anomaly Detection
15.1 Problem Motivation
所谓的异常检测问题就是:我们希望知道这个新的数据是否有某种异常,它是否符合我们模型应该得到的结果。
我们所构建的模型应该能根据该测试数据的位置告诉我们其属于一组数据的可能性 $p(x)$。
这种方法称为密度估计,表达如下:
15.2 Gaussian Distribution
回顾高斯分布的基本知识。
通常如果我们认为变量 $x$ 符合高斯分布 $x \sim N(\mu, \sigma^2)$则其概率密度函数为:
我们可以利用已有的数据来预测总体中的$μ$和$σ^2$的计算方法如下:
机器学习中对于方差我们通常只除以$m$而非统计学中的$(m-1)$
15.3 Algorithm
一旦我们获得了平均值和方差的估计值,给定新的一个训练实例,根据模型计算 $p(x)$:
当$p(x) < \varepsilon$时,为异常。
【Python 代码】
单变量
1 | |
15.4 Developing and Evaluating an Anomaly Detection System
异常检测算法是一个非监督学习算法,意味着我们无法根据结果变量 $ y$ 的值来告诉我们数据是否真的是异常的。我们需要另一种方法来帮助检验算法是否有效。当我们开发一个异常检测系统时,我们从带标记(异常或正常)的数据着手,我们从其中选择一部分正常数据用于构建训练集,然后用剩下的正常数据和异常数据混合的数据构成交叉检验集和测试集。
例如:我们有10000台正常引擎的数据,有20台异常引擎的数据。 我们这样分配数据:
6000台正常引擎的数据作为训练集
2000台正常引擎和10台异常引擎的数据作为交叉检验集
2000台正常引擎和10台异常引擎的数据作为测试集
具体的评价方法如下:
- 根据测试集数据,我们估计特征的平均值和方差并构建$p(x)$函数
- 对交叉检验集,我们尝试使用不同的$\varepsilon$值作为阀值,并预测数据是否异常,根据$F1$值或者查准率与查全率的比例来选择 $\varepsilon$
- 选出 $\varepsilon$ 后,针对测试集进行预测,计算异常检验系统的$F1$值,或者查准率与查全率之比
15.5 Anomaly Detection vs. Supervised Learning
之前我们构建的异常检测系统也使用了带标记的数据,与监督学习有些相似,下面的对比有助于选择采用监督学习还是异常检测:
两者比较:
| 异常检测 | 监督学习 |
|---|---|
| 非常少量的正向类(异常数据 $y=1$), 大量的负向类($y=0$) | 同时有大量的正向类和负向类 |
| 根据非常少量的正向类数据来训练算法。 | 有足够多的正向类实例,足够用于训练算法。 |
| 未来遇到的异常可能与已掌握的异常、非常的不同。 | 未来遇到的正向类实例可能与训练集中的非常近似。 |
| 例如: 欺诈行为检测 生产(例如飞机引擎)检测数据中心的计算机运行状况 | 例如:邮件过滤器 天气预报 肿瘤分类 |
15.6 Choosing What Features to Use
异常检测假设特征符合高斯分布,如果数据的分布不是高斯分布,异常检测算法也能够工作,但是最好还是将数据转换成高斯分布,例如使用对数函数:$x= log(x+c)$,其中 $c$ 为非负常数; 或者 $x=x^c$,$c$为 0-1 之间的一个分数,等方法。
一个常见的问题是一些异常的数据可能也会有较高的$p(x)$值,因而被算法认为是正常的。这种情况下误差分析能够帮助我们,我们可以分析那些被算法错误预测为正常的数据,观察能否找出一些问题。我们可能能从问题中发现我们需要增加一些新的特征,增加这些新特征后获得的新算法能够帮助我们更好地进行异常检测。
15.7 Multivariate Gaussian Distribution
在多元高斯分布模型中,我们将构建特征的协方差矩阵,用所有的特征一起来计算 $p(x)$。
我们首先计算所有特征的平均值,然后再计算协方差矩阵:
注:其中$\mu $ 是一个向量,其每一个单元都是原特征矩阵中一行数据的均值。最后我们计算多元高斯分布的$p\left( x \right)$:
原高斯分布模型和多元高斯分布模型的比较:
| 原高斯分布模型 | 多元高斯分布模型 |
|---|---|
| 不能捕捉特征之间的相关性 但可以通过将特征进行组合的方法来解决 | 自动捕捉特征之间的相关性 |
| 计算代价低,能适应大规模的特征 | 计算代价较高 训练集较小时也同样适用 |
| 必须要有 $m>n$,不然的话协方差矩阵$\Sigma$不可逆的,通常需要 $m>10n$ 另外特征冗余也会导致协方差矩阵不可逆 |
原高斯分布模型被广泛使用着,如果特征之间在某种程度上存在相互关联的情况,我们可以通过构造新新特征的方法来捕捉这些相关性。
如果训练集不是太大,并且没有太多的特征,我们可以使用多元高斯分布模型。
【Python 代码】
多变量
1 | |
from sklearn.model_selection import train_test_split 自动分成两部分
16. Recommender Systems
此部分在 Recommender System:Classical RS 有更详细的笔记,在此忽略。
Week 10 : Large Scale Machine Learning
17. Gradient Descent with Large Database
17.1 Stochastic Gradient Descent
如果我们一定需要一个大规模的训练集,我们可以尝试使用随机梯度下降法来代替批量梯度下降法。
在随机梯度下降法中,我们定义代价函数为一个单一训练实例的代价:
随机梯度下降算法为:首先对训练集随机“洗牌”,然后:
Repeat (usually anywhere between1-10){
for $i = 1:m${
$\theta:=\theta_{j}-\alpha\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) x_{j}^{(i)}$
(for $j=0:n$)
}
}
随机梯度下降算法在每一次计算之后便更新参数 $\theta $ ,而不需要首先将所有的训练集求和,在梯度下降算法还没有完成一次迭代时,随机梯度下降算法便已经走出了很远。但是这样的算法存在的问题是,不是每一步都是朝着”正确”的方向迈出的。因此算法虽然会逐渐走向全局最小值的位置,但是可能无法站到那个最小值的那一点,而是在最小值点附近徘徊。
17.2 Mini-Batch Gradient Descent
小批量梯度下降算法是介于批量梯度下降算法和随机梯度下降算法之间的算法,每计算常数$b$次训练实例,便更新一次参数 $\theta $ 。
Repeat {
for $i = 1:m${
$\theta:=\theta_{j}-\alpha \frac{1}{b} \sum_{k=i}^{i+b-1}\left(h_{\theta}\left(x^{(k)}\right)-y^{(k)}\right) x_{j}^{(k)}$
(for $j=0:n$)
$ i +=10 $
}
}
通常我们会令 $b$ 在 2-100 之间。这样做的好处在于,我们可以用向量化的方式来循环 $b$个训练实例,如果我们用的线性代数函数库比较好,能够支持平行处理,那么算法的总体表现将不受影响(与随机梯度下降相同)。
17.3 Stochastic Gradient Descent Convergence
在随机梯度下降中,我们在每一次更新 $\theta $ 之前都计算一次代价,然后每$x$次迭代后,求出这$x$次对训练实例计算代价的平均值,然后绘制这些平均值与$x$次迭代的次数之间的函数图表。
当我们绘制图表时,可能会得到一个颠簸不平但是不会明显减少的函数图像。我们可以增加$\alpha$来使得函数更加平缓,也许便能看出下降的趋势了;对于函数图表仍然是颠簸不平且不下降的,那么我们的模型本身可能存在一些错误。
如果我们得到的曲线不断地上升,那么我们可能会需要选择一个较小的学习率$\alpha$。我们也可以令学习率随着迭代次数的增加而减小,例如令:
17.4 Online Learning
今天,许多大型网站或者许多大型网络公司,使用不同版本的在线学习机制算法,从大批的涌入又离开网站的用户身上进行学习。特别要提及的是,如果有一个由连续的用户流引发的连续的数据流进入你的网站,你能做的是使用一个在线学习机制,从数据流中学习用户的偏好,然后使用这些信息来优化一些关于网站的决策。在线学习算法指的是对数据流而非离线的静态数据集的学习。许多在线网站都有持续不断的用户流,对于每一个用户,网站希望能在不将数据存储到数据库中便顺利地进行算法学习。
在线学习的算法与随机梯度下降算法有些类似,我们对单一的实例进行学习,而非对一个提前定义的训练集进行循环。一旦对一个数据的学习完成了,我们便可以丢弃该数据,不需要再存储它了。这种方式的好处在于,我们的算法可以很好的适应用户的倾向性,算法可以针对用户的当前行为不断地更新模型以适应该用户。每次交互事件并不只产生一个数据集,例如,我们一次给用户提供3个物流选项,用户选择2项,我们实际上可以获得3个新的训练实例,因而我们的算法可以一次从3个实例中学习并更新模型。
17.5 Map Reduce and Data Parallelism
映射化简和数据并行对于大规模机器学习问题而言是非常重要的概念。之前提到,如果我们用批量梯度下降算法来求解大规模数据集的最优解,我们需要对整个训练集进行循环,计算偏导数和代价,再求和,计算代价非常大。如果我们能够将我们的数据集分配给不多台计算机,让每一台计算机处理数据集的一个子集,然后我们将计所的结果汇总在求和。这样的方法叫做映射简化。
具体而言,如果任何学习算法能够表达为,对训练集的函数的求和,那么便能将这个任务分配给多台计算机(或者同一台计算机的不同CPU 核心),以达到加速处理的目的。
Week 11 : Application Example : Photo OCR
18. Photo OCR
18.1 Problem Description and Pipeline
图像文字识别应用所作的事是,从一张给定的图片中识别文字。这比从一份扫描文档中识别文字要复杂的多。
为了完成这样的工作,需要采取如下步骤:
文字侦测(Text detection)——将图片上的文字与其他环境对象分离开来
字符切分(Character segmentation)——将文字分割成一个个单一的字符
字符分类(Character classification)——确定每一个字符是什么
18.2 Sliding Windows
滑动窗口是一项用来从图像中抽取对象的技术。假使我们需要在一张图片中识别行人,首先要做的是用许多固定尺寸的图片来训练一个能够准确识别行人的模型。然后我们用之前训练识别行人的模型时所采用的图片尺寸在我们要进行行人识别的图片上进行剪裁,然后将剪裁得到的切片交给模型,让模型判断是否为行人,然后在图片上滑动剪裁区域重新进行剪裁,将新剪裁的切片也交给模型进行判断,如此循环直至将图片全部检测完。然后,我们按比例放大剪裁的区域,以新的尺寸对图片进行剪裁,将新剪裁的切片按比例缩小至模型所采纳的尺寸,交给模型进行判断,如此循环。
滑动窗口技术也被用于文字识别,首先训练模型能够区分字符与非字符,然后,运用滑动窗口技术识别字符,一旦完成了字符的识别,我们将识别得出的区域进行一些扩展,然后将重叠的区域进行合并。接着我们以宽高比作为过滤条件,过滤掉高度比宽度更大的区域(认为单词的长度通常比高度要大)。
最后一个阶段是字符分类阶段,利用神经网络、支持向量机或者逻辑回归算法训练一个分类器即可。
18.3 Getting Lots of Data and Artificial Data
如果我们的模型是低方差的,那么获得更多的数据用于训练模型,是能够有更好的效果的。问题在于,我们怎样获得数据,数据不总是可以直接获得的,我们有可能需要人工地创造一些数据。
以我们的文字识别应用为例,我们可以字体网站下载各种字体,然后利用这些不同的字体配上各种不同的随机背景图片创造出一些用于训练的实例,这让我们能够获得一个无限大的训练集。这是从零开始创造实例。
另一种方法是,利用已有的数据,然后对其进行修改,例如将已有的字符图片进行一些扭曲、旋转、模糊处理。只要我们认为实际数据有可能和经过这样处理后的数据类似,我们便可以用这样的方法来创造大量的数据。
有关获得更多数据的几种方法:
1. 人工数据合成
2. 手动收集、标记数据
3. 众包
18.4 Ceiling Analysis_ What Part of the Pipeline to Work on Next
在机器学习的应用中,我们通常需要通过几个步骤才能进行最终的预测,我们如何能够知道哪一部分最值得我们花时间和精力去改善呢?这个问题可以通过上限分析来回答。
流程图中每一部分的输出都是下一部分的输入,上限分析中,我们选取一部分,手工提供100%正确的输出结果,然后看应用的整体效果提升了多少。假使我们的例子中总体效果为72%的正确率。
如果我们令文字侦测部分输出的结果100%正确,发现系统的总体效果从72%提高到了89%。这意味着我们很可能会希望投入时间精力来提高我们的文字侦测部分。
接着我们手动选择数据,让字符切分输出的结果100%正确,发现系统的总体效果只提升了1%,这意味着,我们的字符切分部分可能已经足够好了。
最后我们手工选择数据,让字符分类输出的结果100%正确,系统的总体效果又提升了10%,这意味着我们可能也会应该投入更多的时间和精力来提高应用的总体表现。
19. 致谢
至此《机器学习》的课程就全部结束了。非常感谢 Dr. Andrew Ng 带我入了 Machine Learning 这个大坑,让我接触到了许多大学课程所学不到的知识。同时这门课程的内容确实非常适合没有基础的小白入门,它甚至包含了一些数学基础复习。并且课后的练习让在课上没有完全听懂的我得以抓住每节课的知识点,在课后理解复习。令人欣喜的是这门课同时还传授了许多构建模型实战运用的技巧,虽然在几年前第一次听这门课时并没有太过注意,但当现在的我已经有足够的基础做过一些研究后,才发现这些技巧和经验是十分可贵的!最后再次感谢教授耐心的指导和精彩的教学,以及每节课上的灿烂笑容!